常说的字符集和编码区别,其实就是编码字符集和字符集编码的区别,其实,单单如果只是说字符集,没有任何编码的概念的话,那么字符集其实仅仅是一个简单的字符的集合,或者说是一个抽象的字符的集合,包括文字,符号等等,不参与任何存储形式,只是存在这么各种各样标准的字符的集合
如果仅仅是抽象的字符集,我们是无需拿出讨论的,因为没有任何异议,通俗易懂,而常说的字符集指的编码字符集,比如常见的 unicode、ascii、gb2312、gbk等,这些我们常称做为字符集(其实是编码字符集),这些字符集,比如unicode其实本质上是已经“编码”过的字符集,即每个字符都有唯一的整数编号,每个字符都有自己特有的编号,同一个字符在不同编码字符集中编号也会不同,当然很多编码字符集都是ascll的超集,所以ascll字符集的编号与很多编码字符集中编号都一样,比如英文字母“A”,在ASCII及Unicode及GB2312中,均是第0×41个字符,说到这里朋友一定注意到了我上面再描述“ unicode其实本质上是已经“编码”过的字符集”中的“编码”二字加了双引号,我要强调的是这里的“编码”并不是真的我下面要说的编码,这里只是为每个字符编了一个对应的编号,但是我们还是习惯专业的称呼为“编码字符集”
我们经常说“文章采用的是utf-8编码方式”
我对于这个编码方式的意义,个人理解是 将一个字符的整数编号用一个什么二进制的整数值来对应并在计算机存储。这和上面说的编码字符集中的“编码”千差万别,这里我们称之为“字符集编码”,即我们常说的编码
说到这里,很多人会觉得那么unicode和utf-8的区别在哪里?既然上文说到unicode是编码字符集,那么utf-8又是什么?就是常说的编码?
“文章采用的是utf-8编码方式”,个人觉得准确的说法是“文章采用的是基于unicode编码字符集的utf-8的编码方案”,即
即unicode本身作为编码字符集没有任何存储形式,只是一个编号和字符对应的表而已,如何在计算机存储?你可能想到了干脆直接把编号当作二进制数值来直接存储,那么为什么不这么做呢?这也算是一种字符集编码方案,就是基于unicode编码字符集的utf-32编码方案,那么有没有更加智能一点的编码方案呢?为什么会没有呢?那就是utf-8、utf-16等等, 等等,在我解释为何要用utf-8编码方案的时候,我必须说明一件事情:如下
我在上一篇文章《你不知道的 页面编码,浏览器选择编码,get,post各种乱码由来》中说过:“如何查看中文字符的十六进制字符串?方法:BitConverter.ToString(System.Text.Encoding.UTF8.GetBytes(“阿道夫”));” 请注意我可以改为“System.Text.Encoding.Unicode.GetBytes” 如下图是vs2013 Encoding键入“.”后的智能提示
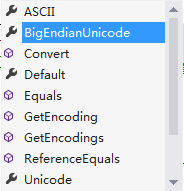
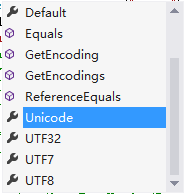
(列表过长,用两幅图分别截图)
上图有两个疑问:
1、如果说unicode是编码字符集,为何会出现在和utf-8这种编码方案并列的列表中?
2、ASCII或者gb2312都是编码字符集为何也会出现在和utf-8这种编码方案并列的列表中?
我们假设有两个猜测:
1、此处的unicode并不是真正的unicode编码字符集,可能只是一种和unicode编码字符集关系非常紧密的一种编码方案
2、ASCII或者gb2312(其实就是图中的Default,即操作系统当前的编码,国内一般为gb2312)是编码字符集没有错,但是对于ASCII或者gb2312都只有唯一一种编码,那么我称呼它们为ASCII编码或者GB2312编码也没有问题,既然这样,那我把ascii和gb2312加入和utf-8这种编码方案并列的列表中也理所当然?
我的两个假设,很快得到论证
1、在Encoding 的元数据看到:
//
// 摘要:
// 获取使用 Little-Endian 字节顺序的 UTF-16 格式的编码。
//
// 返回结果:
// 使用 Little-Endian 字节顺序的 UTF-16 格式的编码。
public static Encoding Unicode { get; }
这里解释在这里的unicode其实本质上“获取使用 Little-Endian 字节顺序的 UTF-16 格式的编码”,即使基于unicode编码字符集的utf-16编码方案,类似的有BigEndianUnicode(获取使用 Big Endian 字节顺序的 UTF-16 格式的编码)
2、一般的ASCII或者gb2312,我们可以称呼为ASCII字符集也可以称呼为ASCII编码,只是意义不同而已,因为对于ASCII编码字符集或者gb2312编码字符集都只有唯一一种编码,就是ASCII编码和GB2312编码,那么列表中显示的ASCII和GB2312指的不是编码字符集而是ASCII和GB2312的编码方案,我想正是这种原因,才在很多时候,不管是字符集赋值还是编码方案赋值都可以直接用gb2312或者ascii,比如:
Encoding gb2312 = Encoding.GetEncoding(“gb2312″);
Response.ContentEncoding = gb2312;//编码
Response.Charset=”gb2312″;//字符集
总结下的说:
就是unicode是字符集,不是编码!但是ascii(gb2312)是字符集,这个说法肯定正确,但是我表达为“ascii编码”也不能说大错特错,但是这种说法让人误解,如果一定要说那么就说“ascii编码字符集的编码”
如果理解上面两个假设的论证道理,那么我们继续讨论之前暂停的话题,即“解释为何要用utf-8等编码方案(其他utf编码方案类似)”
utf-8将很大一部分基于unicode编码字符集的字符的整数编号作了变换后存储在计算机中。(引用)以“汉”字为例,“汉”的Unicode值为0x6C49,但其编码为UTF-8格式后的值为0xE6B189(注意到变成了三个字节)。对于UTF-16编码方案,则是对unicode编码字符集中的前65536个字符编号都不做变换,直接作为计算机存储时使用的值(对65536以后的字符,仍然要做变换),例如“汉”字的Unicode编号为0x6C49,那么经过UTF-16编码后存储在计算机上时,它的表示仍为0x6C49,对于UTF-32编码方案,他对所有的Unicode字符均不做变换,直接使用编号存储,只是这种编码方案太浪费存储空间(就连1个字节就可以搞定的英文字符,它都必须使用4个字节)
既然unicode编码字符集有如此多的编码方案,那么
utf-8,字母数字符号等占1字节,汉字占三字节
utf-16,对unicode编码字符集中的前65536个字符都占两个字节
utf-32,全部占四字节
如果还有人问:
“unicode编码每个字符占几个字节”,我们可以理直气壮的说,第一unicode不是编码!第二每个字符具体占多少字节是要看编码方案!
很多面试题会问:
string param = "abc阿道夫"; int length1 = System.Text.Encoding.Unicode.GetBytes(param).Length;//别忘了这里的unicode本质是utf-16编码方案 int length2 = param.Length;
那么答案就是12和6了
最后,对于gb2312或者ascii编码字符集的字符的编号就是直接存储在计算机中的二进制数,也就是说gb2312和ascii编码字符集都只有一种编码方案,因为在gb2312编码字符集中的ascii字符集部分的编号并没有变化(即和ascii编码字符集中的编码一致),所以gb2312的ascii部分字符存入计算机的二进制数还是占用1个字节,而中文字符存入计算机的二进制数也是该中文字符在gb2312编码字符集中的编号,该编号一般转换成二进制数都占两个字节,这个过程也就变成了所谓的gb2312编码
如果上面的改为System.Text.Encoding.Default.GetBytes(param).Length,则值就是9和6了
如果需要了解更加深入的编码内部原理请参考:
哈尔滨品用软件有限公司致力于为哈尔滨的中小企业制作大气、美观的优秀网站,并且能够搭建符合百度排名规范的网站基底,使您的网站无需额外费用,即可稳步提升排名至首页。欢迎体验最佳的哈尔滨网站建设。